DeepSeek OCR 2: ثورة في معالجة وفهم المستندات ذكيًا
أطلقت DeepSeek رسميًا نموذج DeepSeek-OCR 2، وهو نظام ثوري للتعرف الضوئي على الحروف يمثل تحولًا جذريًا من المسح الخطي التقليدي إلى نموذج يفسر الصور بناءً على "المنطق البصري البشري".
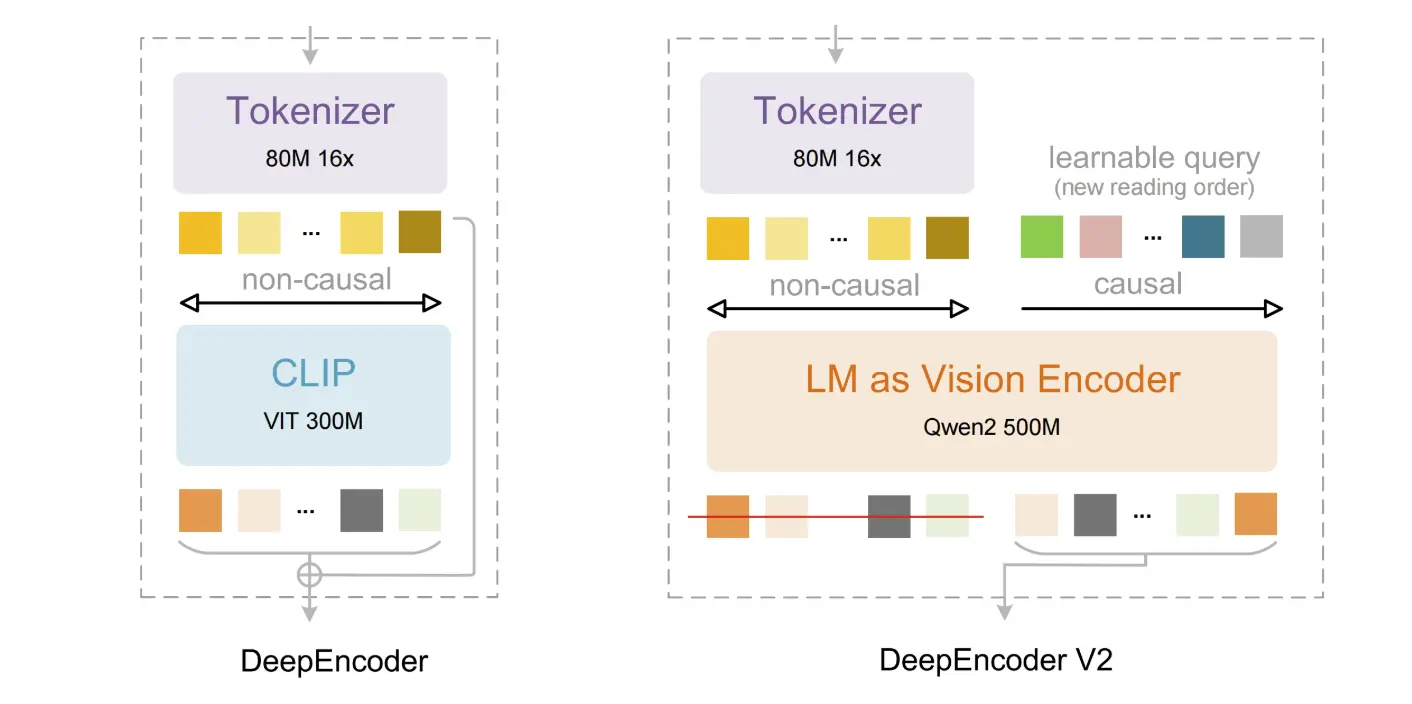
DeepEncoder V2: التدفق البصري السببي
في صميم هذا الإصدار تأتي بنية DeepEncoder V2. على عكس أدوات التعرف الضوئي التقليدية التي تعالج المستندات سطرًا بسطر بدقة، يستخدم DeepSeek-OCR 2 آلية "التدفق البصري السببي". يقوم النموذج بإعادة ترتيب مكونات الصورة ديناميكيًا بناءً على المعنى الدلالي، محاكيًا طريقة قراءة البشر لصفحة معقدة — حيث يستوعب أولاً التخطيط العام والأعمدة والعلاقات قبل الخوض في التفاصيل الدقيقة.
يعمل هذا الأسلوب على تحسين الأداء بشكل كبير في التخطيطات المعقدة، مثل المستندات والجداول ذات النصوص والهياكل المختلطة، من خلال تمكين الذكاء الاصطناعي من "رؤية" السياق العام أولاً.
كفاءة لا مثيل لها ومواصفات تقنية
يقدم DeepSeek-OCR 2 ميزة "الضغط البصري للسياق"، القادرة على تمثيل المحتوى بـ رموز (Tokens) أقل بـ 20 ضعفاً مقارنة بالنماذج التقليدية. يتيح هذا التحسين الهائل في الكفاءة ما يلي:
- الدقة الديناميكية: يستخدم النموذج استراتيجية دقة مرنة (افتراضيًا الرموز المركبة مثل
(0-6)×768×768 + 1×1024×1024) لتحقيق التوازن بين التفاصيل والسرعة. - <strong>تقليل هائل</strong> في وقت الحوسبة واستهلاك الذاكرة.
- <strong>قابلية التوسع</strong> لمهام استيعاب المستندات واسعة النطاق التي قد تشكل عبئاً كبيراً على النماذج الأخرى.
الأداء واختبارات القياس
تظهر التقييمات على اختبارات القياس مثل <strong>OmniDocBench v1.5</strong> تحسنًا بنسبة 3.73% مقارنة بالمعايير السابقة. والأهم من ذلك، أنه يطابق أو يتفوق على قدرات كبار مزودي السحابة (Google Cloud Vision و AWS Textract) مع تشغيله بكفاءة أكبر بشكل ملحوظ على الأجهزة المحلية.
وهو يتميز بشكل خاص في:
- الحفاظ على هياكل المستندات المعقدة.
- معالجة أكثر من 100 لغة مختلفة.
- معالجة المحتوى المتخصص مثل الصيغ الكيميائية (SMILES).
المصدر المفتوح والتوافر
نموذج DeepSeek-OCR 2 مفتوح المصدر بالكامل بموجب رخصة MIT، مما يعزز التزام DeepSeek بالذكاء الاصطناعي المتاح للجميع.
التثبيت عبر Git
git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.gitمناقشات المجتمع
ما الذي يفعله عباقرة الرياضيات في الصين لتحسين النماذج اللغوية الكبيرة؟ هذا يشبه دواء Ozempic للنماذج الكبيرة بـ 10 أضعاف الكفاءة!
تطورات مذهلة! التركيز على الترتيب المنطقي البصري الشبيه بالبشر في مسح الصور قد يحدث ثورة في معالجة المستندات. متحمس لرؤية التأثير على دقة التعرف الضوئي. عمل رائع لفريق DeepSeek!
رائع جداً، الآن لدينا ذكاء اصطناعي يفعل ما يفعله البشر تماماً، يتخطى العنوان والفقرة الأولى ويشعر بالانزعاج لأن الفقرة الثانية لم تحدد سياق المشهد. 😂 عبقري.
أخيرًا، نظام OCR يفهم سياق التخطيط العام بدلاً من مجرد المسح الشبكي العشوائي.
هل لدى أحد فكرة عن كيفية مقارنته بنموذج Florence؟
@grok هل يمكنني تشغيل هذا على جهاز MBP m3؟ أو على خادم افتراضي VPS وما هي السرعة المتوقعة؟