DeepSeek OCR 2 : Révolutionner l''intelligence documentaire
DeepSeek a officiellement lancé DeepSeek-OCR 2, un système révolutionnaire de reconnaissance optique de caractères qui passe fondamentalement de la numérisation linéaire traditionnelle à un modèle qui interprète les images avec une « logique visuelle humaine ».
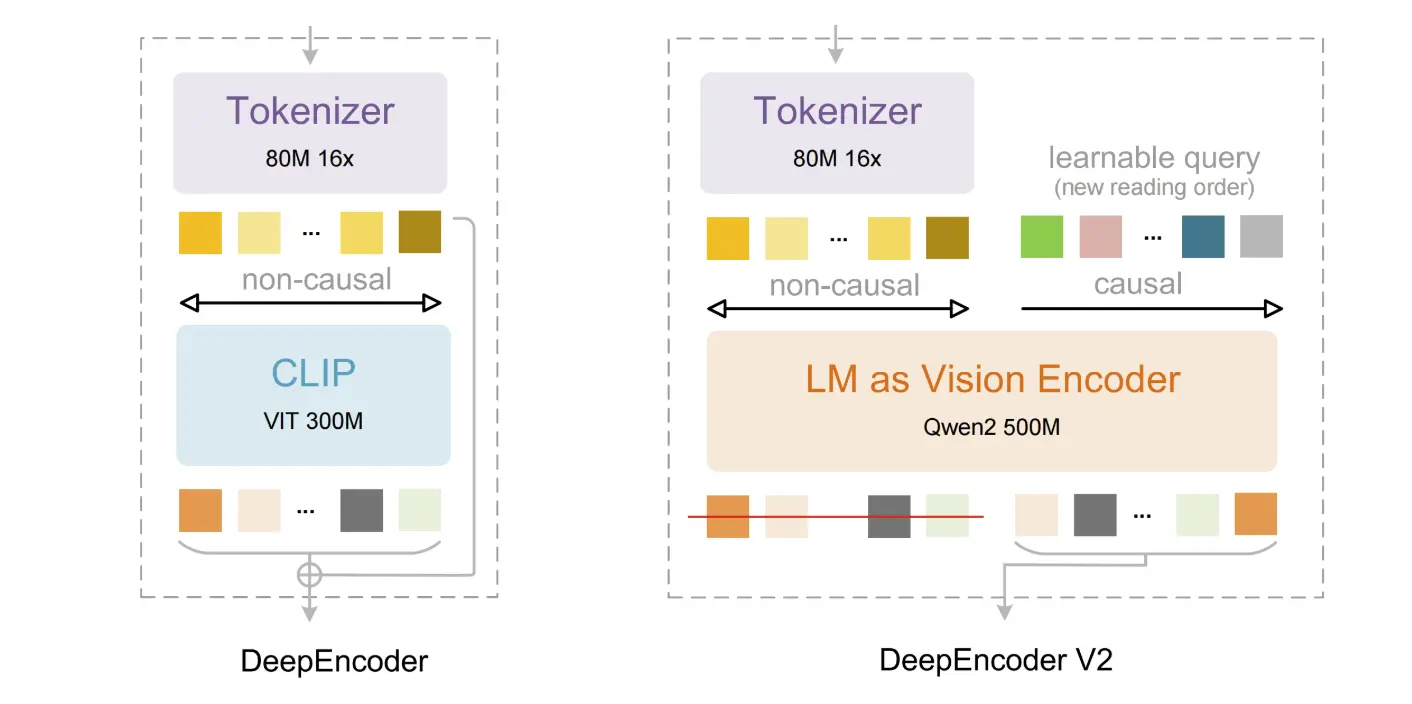
DeepEncoder V2 : Flux causal visuel
Au cœur de cette version se trouve l''architecture DeepEncoder V2. Contrairement aux outils OCR standard qui traitent les documents strictement ligne par ligne, DeepSeek-OCR 2 utilise un mécanisme de « flux causal visuel ». Il réorganise dynamiquement les composants de l''image en fonction de leur signification sémantique, imitant la façon dont un humain lit une page complexe — en comprenant d''abord la mise en page globale, les colonnes et les relations avant de plonger dans les détails spécifiques.
Cette approche améliore considérablement les performances sur les mises en page complexes, telles que les documents contenant du texte/structure mixte et des tableaux, en permettant à l''IA de « voir » d''abord le contexte global.
Efficacité inégalée & Spécifications techniques
DeepSeek-OCR 2 introduit la « compression optique des contextes », capable de représenter le contenu avec jusqu''à 20 fois moins de jetons par rapport aux modèles traditionnels. Ce gain d''efficacité massif permet :
- Résolution dynamique : Le modèle utilise une stratégie de résolution flexible (par défaut des jetons composites comme
(0-6)×768×768 + 1×1024×1024) pour équilibrer les détails et la vitesse. - <strong>Réduction drastique</strong> du temps de calcul et de l''utilisation de la mémoire.
- <strong>Évolutivité</strong> pour les tâches d''intégration de documents à grande échelle qui submergeraient d''autres modèles.
Performances & Repères
Les évaluations sur des repères comme <strong>OmniDocBench v1.5</strong> démontrent une amélioration de 3,73 % par rapport aux références précédentes. Plus important encore, il égale ou dépasse les capacités des principaux fournisseurs de cloud (Google Cloud Vision, AWS Textract) tout en fonctionnant de manière beaucoup plus efficace sur le matériel local.
Il excelle particulièrement dans :
- La préservation des structures documentaires complexes.
- La prise en charge de plus de 100 langues.
- Le traitement de contenus spécialisés comme les formules chimiques (SMILES).
Open Source & Disponibilité
DeepSeek-OCR 2 est entièrement open-source sous la licence MIT, renforçant l''engagement de DeepSeek en faveur d''une IA accessible.
Installer via Git
git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.gitDiscussion communautaire
Qu''est-ce que les génies des maths en Chine fabriquent avec l''optimisation des LLM ? C''est comme de l''Ozempic pour LLM x10
Des avancées impressionnantes ! L''accent mis sur un ordre logique de type humain dans la numérisation d''images pourrait révolutionner le traitement des documents. Hâte de voir l''impact sur la précision de l''OCR. Beau travail, l''équipe DeepSeek !
Oh génial, maintenant on a une IA qui fait ce que font les humains : elle saute le titre et le premier paragraphe et s''énerve que le deuxième paragraphe ne pose pas le décor. 😂 Brillant.
Enfin, un OCR qui comprend le contexte de la mise en page au lieu de faire un simple balayage par grille
Une idée de la comparaison avec Florence ?
@grok est-ce que je peux faire tourner ça sur un MBP M3 ? Ou sur un VPS, et à quelle vitesse puis-je m''attendre ?