DeepSeek OCR 2:文書インテリジェンスに革命をもたらす
DeepSeekは、画期的な光学文字認識システムであるDeepSeek-OCR 2を正式に発表しました。これは、従来の線形スキャンから、「人間の視覚ロジック」を用いて画像を解釈するモデルへの根本的な転換を意味します。
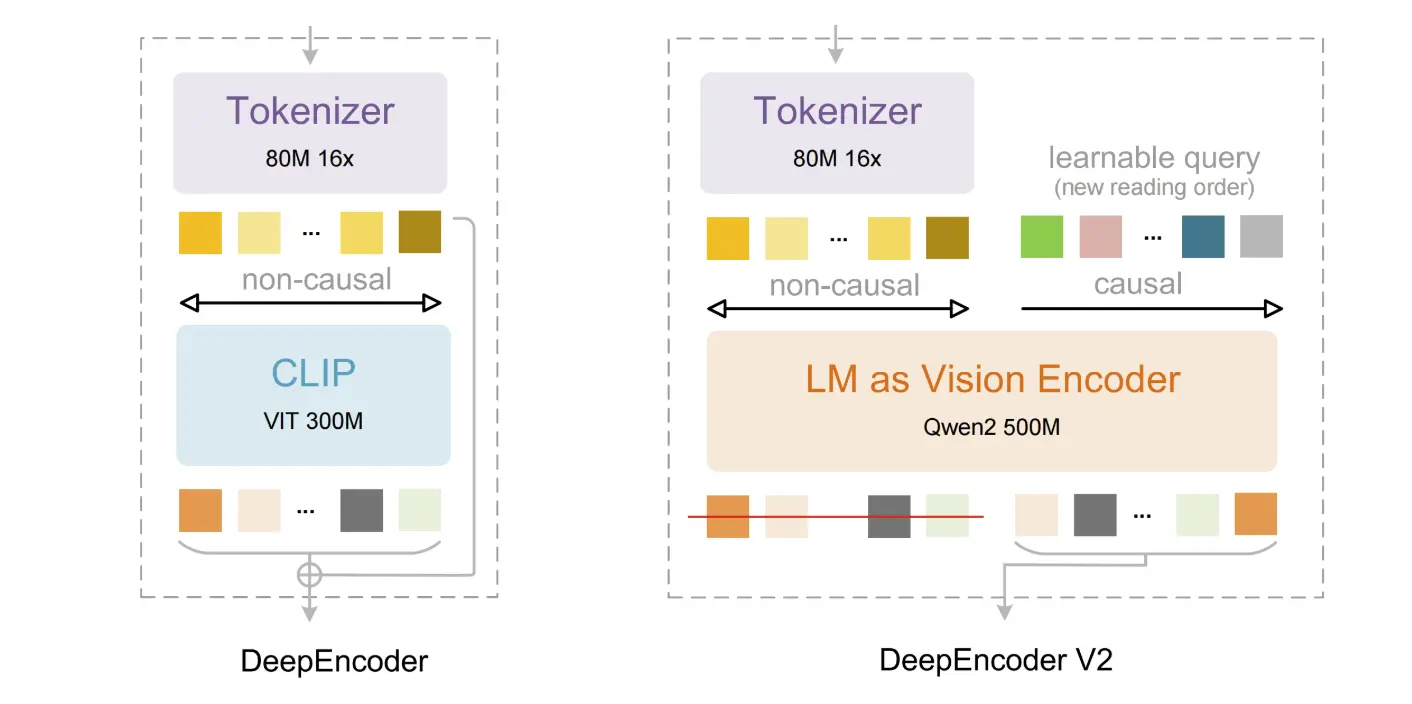
DeepEncoder V2:視覚的因果フロー
このリリースの核心は、DeepEncoder V2アーキテクチャです。文書を厳密に1行ずつ処理する標準的なOCRツールとは異なり、DeepSeek-OCR 2は「視覚的因果フロー(Visual Causal Flow)」メカニズムを採用しています。これは、詳細な部分に入る前に、まずページ全体のレイアウト、列、および関係性を理解するという、人間が複雑なページを読む方法を模倣し、意味に基づいて画像の構成要素を動的に再配置します。
このアプローチは、AIがまず全体の文脈を「見る」ことを可能にすることで、テキストと構造が混在した文書や表などの複雑なレイアウトにおけるパフォーマンスを大幅に向上させます。
比類なき効率性と技術仕様
DeepSeek-OCR 2は「文脈の視覚的圧縮」を導入しており、従来のモデルと比較して最大20倍少ないトークンでコンテンツを表現することができます。この圧倒的な効率向上により、以下が可能になります:
- 動的解像度:モデルは、詳細さと速度のバランスを取るために、柔軟な解像度戦略(デフォルトでは
(0-6)×768×768 + 1×1024×1024のような複合トークン)を利用します。 - 計算時間とメモリ使用量の<strong>劇的な削減</strong>。
- 他のモデルでは処理しきれないような、大規模な文書取り込みタスクへの<strong>スケーラビリティ</strong>。
パフォーマンスとベンチマーク
<strong>OmniDocBench v1.5</strong> などのベンチマークでの評価では、従来のベースラインから3.73%の向上が示されました。さらに重要なことに、ローカルハードウェア上で大幅に効率的に動作しながら、主要なクラウドプロバイダー(Google Cloud Vision、AWS Textract)の実力と同等またはそれを上回っています。
特に以下の点で優れています:
- 複雑な文書構造の維持。
- 100以上の言語への対応。
- 化学式(SMILES)などの専門的なコンテンツの処理。
オープンソースと入手方法
DeepSeek-OCR 2はMITライセンスのもとで完全にオープンソース化されており、アクセシブルなAIに対するDeepSeekのコミットメントを裏付けています。
Gitによるインストール
git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.gitコミュニティでの議論
中国の数学オタクたちはLLMの最適化で一体何をやっているんだ?これはLLM界のオゼンピック(Ozempic)だ。効率が10倍になっている!
素晴らしい進歩です!画像スキャンにおいて人間のような論理的順序に焦点を当てることは、文書処理に革命をもたらす可能性があります。OCRの精度への影響を見るのが楽しみです。DeepSeekチーム、素晴らしい仕事をしました!
素晴らしいね。これで人間とまったく同じことをするAIができたわけだ。タイトルと最初の段落をスキップして、第2段落で状況設定がされていないことにイライラするんだ。😂 見事だ。
ついに、単なるグリッドスキャンではなく、レイアウトの文脈を理解するOCRが登場した。
Florenceモデルと比べてどうなのか、誰か知っていますか?
@grok これをM3チップのMBPで動かすことはできますか?あるいはVPSで動かした場合、どのくらいの速度が期待できますか?