DeepSeek OCR 2: революция в интеллектуальной обработке документов
Компания DeepSeek официально представила модель DeepSeek-OCR 2 — революционную систему оптического распознавания символов, которая знаменует фундаментальный переход от традиционного линейного сканирования к модели, интерпретирующей изображения с использованием «человеческой визуальной логики».
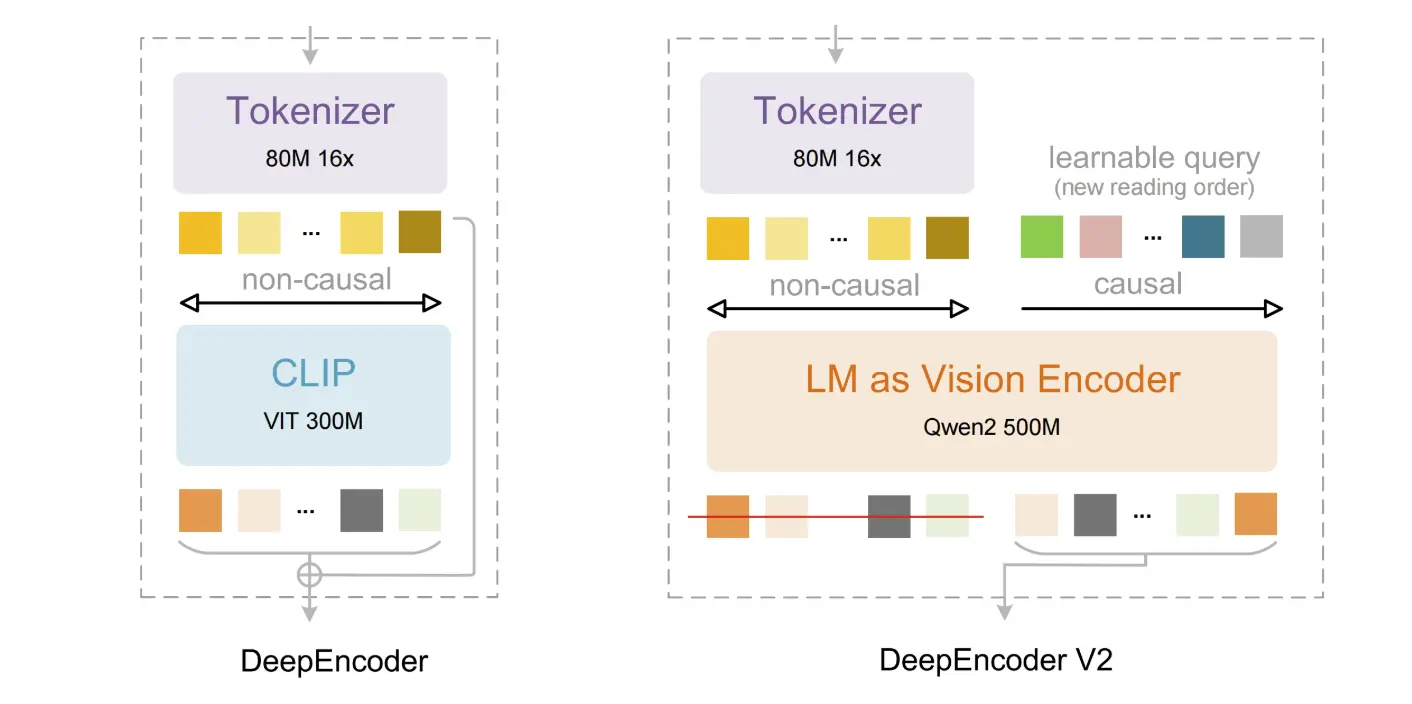
DeepEncoder V2: Причинно-следственный визуальный поток
В основе этой версии лежит архитектура DeepEncoder V2. В отличие от стандартных инструментов OCR, которые обрабатывают документы строго построчно, DeepSeek-OCR 2 использует механизм «визуального причинно-следственного потока». Он динамически перегруппирует элементы изображения в соответствии с семантическим значением, имитируя то, как человек читает сложную страницу: сначала оценивая общую верстку, колонки и связи перед переходом к конкретным деталям.
Такой подход значительно улучшает результаты при работе со сложными макетами, такими как документы со смешанным текстом/структурой и таблицы, позволяя искусственному интеллекту сначала «видеть» общий контекст.
Непревзойденная эффективность и технические характеристики
DeepSeek-OCR 2 представляет технологию «оптического сжатия контекстов», которая способна представлять контент с использованием до 20 раз меньшего количества токенов по сравнению с традиционными моделями. Такой колоссальный прирост эффективности дает:
- Динамическое разрешение: модель использует гибкую стратегию разрешения (по умолчанию составные токены вида
(0-6)×768×768 + 1×1024×1024) для баланса детализации и скорости. - <strong>Радикальное сокращение</strong> времени вычислений и объема используемой памяти.
- <strong>Масштабируемость</strong> для ресурсоемких задач импорта больших массивов документов, которые перегрузили бы другие модели.
Производительность и бенчмарки
Тестирование на бенчмарках уровня <strong>OmniDocBench v1.5</strong> показало улучшение на 3.73% по сравнению с предыдущими базовыми показателями. Что еще важнее, модель сопоставима или превосходит возможности ведущих облачных сервисов (Google Cloud Vision, AWS Textract), работая при этом существенно эффективнее на локальном оборудовании.
Она особенно хороша в:
- Сохранении сложных структур документов.
- Поддержке более 100 языков.
- Обработке специализированного контента, например, химических формул (SMILES).
Открытый исходный код и доступность
Модель DeepSeek-OCR 2 полностью открыта под лицензией MIT, подтверждая стремление компании делать технологии ИИ доступными.
Установка через Git
git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.gitОбсуждение в сообществе
какого черта математические гики в Китае творят с оптимизацией моделей? Это просто Оземпик для LLM, ускорение в 10 раз.
Впечатляющий прогресс! Фокус на человекоподобном логическом порядке сканирования изображений может произвести революцию в обработке документов. С нетерпением жду возможности увидеть влияние на точность OCR. Отличная работа, команда DeepSeek!
О, отлично, теперь у нас есть ИИ, который делает то же, что и люди: пропускает заголовок и первый абзац, а потом раздражается, что второй абзац не вводит в курс дела. 😂 Гениально.
Наконец-то OCR, которое понимает контекст макета, а не просто сканирует по сетке.
Кто-нибудь знает, как она выглядит в сравнении с Florence?
@grok могу ли я запустить это на MBP m3? Или на VPS, и на какую скорость я могу рассчитывать?