DeepSeek OCR 2:引領文件智能理解的革命
DeepSeek 正式發布了 DeepSeek-OCR 2。這是一個開創性的光學字元識別系統,實現了從傳統線性掃描向使用「人類視覺邏輯」解釋影像的模型的根本性轉變。
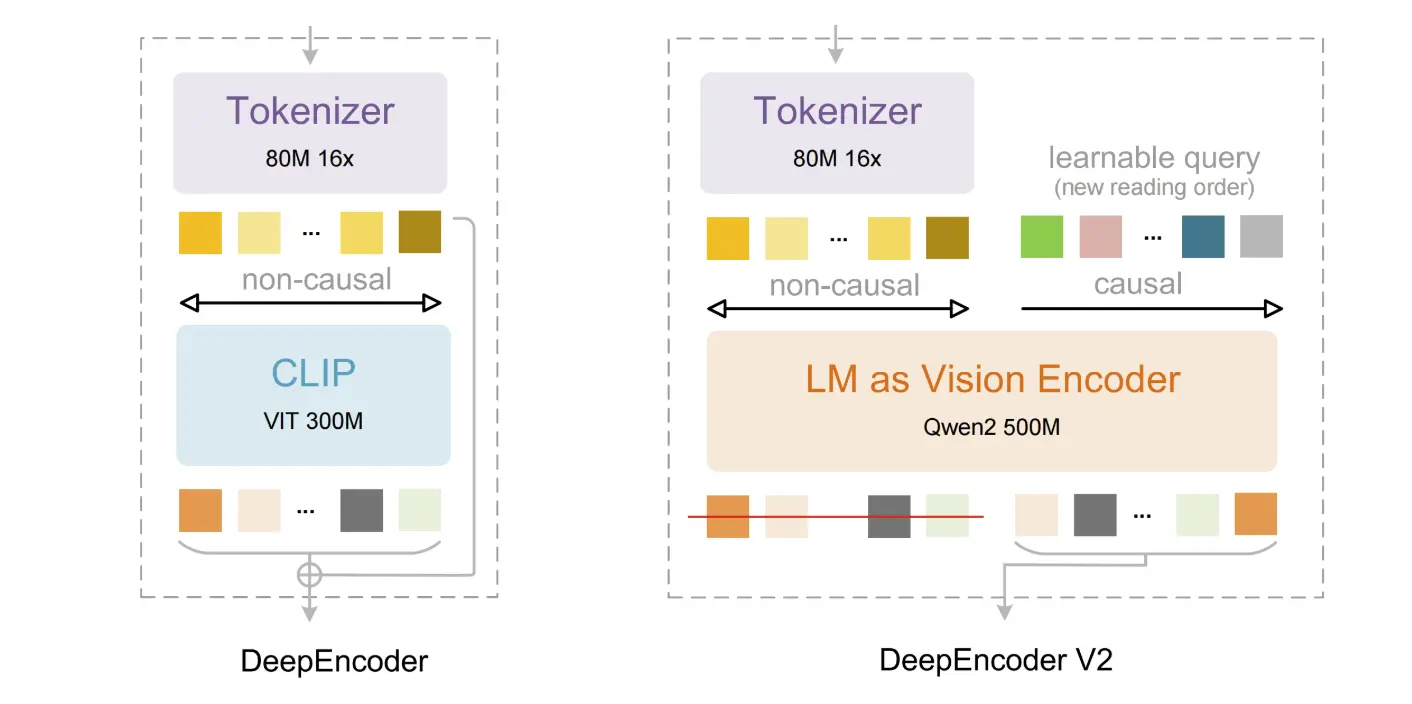
DeepEncoder V2:視覺因果流
本次發布的核心是 DeepEncoder V2 架構。與嚴格逐行處理文件的傳統 OCR 工具不同,DeepSeek-OCR 2 採用了「視覺因果流(Visual Causal Flow)」機制。它根據語意動態重新排列影像組件,模擬人類閱讀複雜頁面的方式——在深入具體細節之前,先理解全局版面、分欄以及元素之間的關係。
這種方法透過讓 AI 先「看清」全局上下文,顯著提升了在混合文字/結構文件和表格等複雜版面上的處理效能。
無與倫比的效率與技術規格
DeepSeek-OCR 2 引入了「上下文視覺壓縮」技術,與傳統模型相比,能夠用減少高達 20 倍的 Token 來表示內容。這一巨大的效率提升帶來了:
- 動態解析度:該模型採用彈性的解析度策略(預設使用複合 Token,如
(0-6)×768×768 + 1×1024×1024),以平衡細節和速度。 - 計算時間和記憶體佔用的<strong>大幅降低</strong>。
- 針對大規模文件輸入任務的<strong>可擴充性</strong>,而這些任務通常會使其他模型過載。
性能與基準測試
在 <strong>OmniDocBench v1.5</strong> 等基準測試上的評估表明,該模型相比之前的基準有 3.73% 的提升。更重要的是,它在本地硬體上運行效率顯著提高的同时,性能媲美甚至超越了主流雲端服務商(Google Cloud Vision、AWS Textract)。
It excels particularly in:
- 完整保留複雜的文件結構。
- 支援超過 100 種語言。
- 處理化學分子式(SMILES)等專業內容。
開源與獲取方式
DeepSeek-OCR 2 在 MIT 許可下完全開源,這進一步踐行了 DeepSeek 致力於推動普惠 AI 的承諾。
透過 Git 安裝
git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.git社區討論
中國的數學天才們在 LLM 優化方面到底做了什麼?這簡直是 LLM 界的司美格魯肽(Ozempic),效率直接翻了 10 倍!
令人讚嘆的進步!影像掃描中對類似人類邏輯順序的關注,可能會徹底改變文件處理。非常期待看到它對 OCR 準確性的影響。DeepSeek 團隊幹得漂亮!
太好了,現在我們有了一個和人類一模一樣的 AI:直接跳過標題和第一段,然後因為第二段沒有交代背景而感到煩躁。😂 絕了。
終於有一個能理解排版上下文,而不是只會進行網格掃描的 OCR 了。
有人知道它和 Florence 相比怎麼樣嗎?
@grok 我可以在 M3 晶片的 MBP 上運行它嗎?或者在 VPS 上運行,速度能達到多少?